Get an email when a new OpenAI model is available via the API

Here's a simple Google Apps Script to monitor for new OpenAI models:
| var AlertEmail = ''; | |
| var OpenAIAPIKey = ''; | |
| function main() { | |
| // we store known models in script properties | |
| var scriptProperties = PropertiesService.getScriptProperties(); | |
| var currentProps = scriptProperties.getProperties(); | |
| var anythingNew = false; | |
| var newText = ''; | |
| // get list of models that the OpenAIAPIKey has access to | |
| var options = { | |
| 'method' : 'get', | |
| 'headers' : { | |
| 'Authorization': 'Bearer ' + OpenAIAPIKey | |
| }, | |
| 'muteHttpExceptions': true | |
| }; | |
| var response = UrlFetchApp.fetch('https://api.openai.com/v1/models', options); | |
| var json = JSON.parse(response.getContentText()); | |
| // chech for new models | |
| if (json.data) { | |
| json.data.forEach(function(model) { | |
| if (!(model.id in currentProps)) { | |
| scriptProperties.setProperty(model.id, model.owned_by); | |
| anythingNew = true; | |
| newText += 'New Model: ' + model.id + '\n'; | |
| Logger.log('New Model: ' + model.id) | |
| } | |
| }); | |
| } else { | |
| Logger.log('Error: ' + response.getContentText()); | |
| } | |
| // send an email if we found anything new | |
| if (anythingNew){ | |
| MailApp.sendEmail(AlertEmail, 'New OpenAI Models on ' + new Date(), newText) | |
| } | |
| } |
To get this running, paste into a new Apps Script project and enable the Gmail API under services. Add your email address and OpenAI API Key at the top. Run a couple of times and you should get an email with all the current models and then nothing the second time unless you get lucky. On Triggers set a scheduled execution with whatever frequency feels good (I use daily) and you're all set.
More Google Apps Script Projects
- Get an email when your security camera sees something new (Apps Script + Cloud Vision)
- Get an email if your site stops being mobile friendly (no longer available)
- Export Google Fit Daily Steps, Weight and Distance to a Google Sheet
- Email Alerts for new Referers in Google Analytics using Apps Script
- Animation of a year of Global Cloud Cover
- Control LIFX WiFi light bulbs from Google Apps Script
- Adding AI to Todoist with Google Apps Script and OpenAI
- How to backup Google Photos to Google Drive automatically after July 2019 with Apps Script
- Using the Todoist API to set a due date on the Alexa integration to-do list (with Apps Script)
- Automate Google PageSpeed Insights and Core Web Vitals Logging with Apps Script
- Using the Azure Monitor REST API from Google Apps Script
- Monitor page index status with Google Sheets, Apps Script and the Google Search Console API
(Published to the Fediverse as: Get an email when a new OpenAI model is available via the API #code #software #appsscript #google #gmail #openai #ai Get an email when a new OpenAI model is available via the API )
Yerba Buena Island Timelapse

Timelapse shot from Panoramic Park at the top of Yerba Buena Island. This features the Point of Infinity sculpture, the Bay Bridge, Treasure Island, Angel Island, Alcatraz, the Golden Gate Bridge and downtown San Francisco.
Related Posts
- Treasure Island
- Both sides of the Golden Gate, a Time Lapse
- Embarcadero
- San Francisco New Year's Eve Timelapse
- San Francisco New Year's Eve Timelapse 2020
(Published to the Fediverse as: Yerba Buena Island Timelapse #timelapse #video #sanfrancisco #baybridge #goldengatebridge #angelisland #treasureisland #alcatraz Panoramic time lapse from Yerba Buena Island (Bay Bridge, Golden Gate Bridge, Islands and San Francisco) )
Set Todoist Label Colors Automatically Using OpenAI Embeddings

From the department of things I wouldn't have bothered with a year ago, here's a python script to set Todoist label colors.
Why? I like a productivity environment with some color and flare, and it also helps to visually recognize what a task relates to. But setting label colors is more clicks than I have patience for.
How? Just figure out embeddings for each available color and then for each label. Use cosine similarity to set the color that best suits each label. Colors will stay consistent for existing labels and new ones will get just a dash of semantic meaning in their assignments.
Here's the code (you need an OpenAI API key and a Todoist API token set as environment variables):
| import os | |
| from todoist_api_python.api import TodoistAPI | |
| from openai import OpenAI | |
| import numpy as np | |
| # Todoist palette colors from https://developer.todoist.com/api/v1#tag/Colors | |
| colors = [ | |
| {"id": 30, "name": "berry_red", "hex": "#B8255F"}, | |
| {"id": 31, "name": "red", "hex": "#DC4C3E"}, | |
| {"id": 32, "name": "orange", "hex": "#C77100"}, | |
| {"id": 33, "name": "yellow", "hex": "#B29104"}, | |
| {"id": 34, "name": "olive_green", "hex": "#949C31"}, | |
| {"id": 35, "name": "lime_green", "hex": "#65A33A"}, | |
| {"id": 36, "name": "green", "hex": "#369307"}, | |
| {"id": 37, "name": "mint_green", "hex": "#42A393"}, | |
| {"id": 38, "name": "teal", "hex": "#148FAD"}, | |
| {"id": 39, "name": "sky_blue", "hex": "#319DC0"}, | |
| {"id": 40, "name": "light_blue", "hex": "#6988A4"}, | |
| {"id": 41, "name": "blue", "hex": "#4180FF"}, | |
| {"id": 42, "name": "grape", "hex": "#692EC2"}, | |
| {"id": 43, "name": "violet", "hex": "#CA3FEE"}, | |
| {"id": 44, "name": "lavender", "hex": "#A4698C"}, | |
| {"id": 45, "name": "magenta", "hex": "#E05095"}, | |
| {"id": 46, "name": "salmon", "hex": "#C9766F"}, | |
| #{"id": 47, "name": "charcoal", "hex": "#808080"}, | |
| #{"id": 48, "name": "grey", "hex": "#999999"}, | |
| {"id": 49, "name": "taupe", "hex": "#8F7A69"}, | |
| ] | |
| # OpenAI Client | |
| oai = OpenAI() | |
| # Embedding helper | |
| def get_embedding(text): | |
| # Replace underscores and hyphens with spaces | |
| formatted_text = text.replace('_', ' ').replace('-', ' ') | |
| response = oai.embeddings.create( | |
| input=formatted_text, | |
| model="text-embedding-3-small" | |
| ) | |
| return response.data[0].embedding | |
| # Add embeddings to each color in the colors list | |
| print("Generating embeddings for colors...") | |
| for color in colors: | |
| color["embedding"] = get_embedding(color["name"]) | |
| # Get API token from environment variable for security | |
| # You need to set this environment variable with your Todoist API token | |
| api_token = os.environ.get("TODOIST_API_TOKEN") | |
| if not api_token: | |
| print("Error: TODOIST_API_TOKEN environment variable not set") | |
| exit(1) | |
| # Initialize the Todoist API client | |
| api = TodoistAPI(api_token) | |
| try: | |
| # Get all labels | |
| labels = api.get_labels() | |
| for label_iter in labels: | |
| for label in label_iter: | |
| embedding = get_embedding(label.name) | |
| # Fix the calculation of similarities - create a proper comparison array | |
| color_embeddings = np.array([color["embedding"] for color in colors]) | |
| # Calculate similarities correctly - each embedding is a 1536-dim vector | |
| similarities = np.array([np.dot(embedding, color_embedding) / | |
| (np.linalg.norm(embedding) * np.linalg.norm(color_embedding)) | |
| for color_embedding in color_embeddings]) | |
| # Find the color with the highest similarity | |
| max_index = np.argmax(similarities) | |
| new_color = colors[max_index]["name"] | |
| print(f"Setting {label.name} to {new_color}") | |
| api.update_label( | |
| label_id=label.id, | |
| color=new_color | |
| ) | |
| except Exception as error: | |
| print(f"Error: {error}") |
Related Posts
- Adding AI to Todoist with Google Apps Script and OpenAI
- Using the Todoist API to set a due date on the Alexa integration to-do list (with Apps Script)
- Style Transfer for Time Lapse Photography
- More Colors
- Upgrading from word2vec to OpenAI
(Published to the Fediverse as: Set Todoist Label Colors Automatically Using OpenAI Embeddings #code #python #openai #todoist #ai Python code that uses OpenAI embeddings to set Todoist task labels to a semantically meaningful color. )
Revolution

Google Pixel 8 Pro 18mm f2.8 1/257s ISO17
Ok, technically it's R:Evolution, towering over the end of Market Street trying to make downtown happen again while gazing at a haphazardly decorated utility box.
Related Posts
(Published to the Fediverse as: Revolution #photo #revolution #sanfrancisco Photo of the R:Evolution sculpture towering over the end of Market Street )
Vibe Coding a Vibe Video Editor
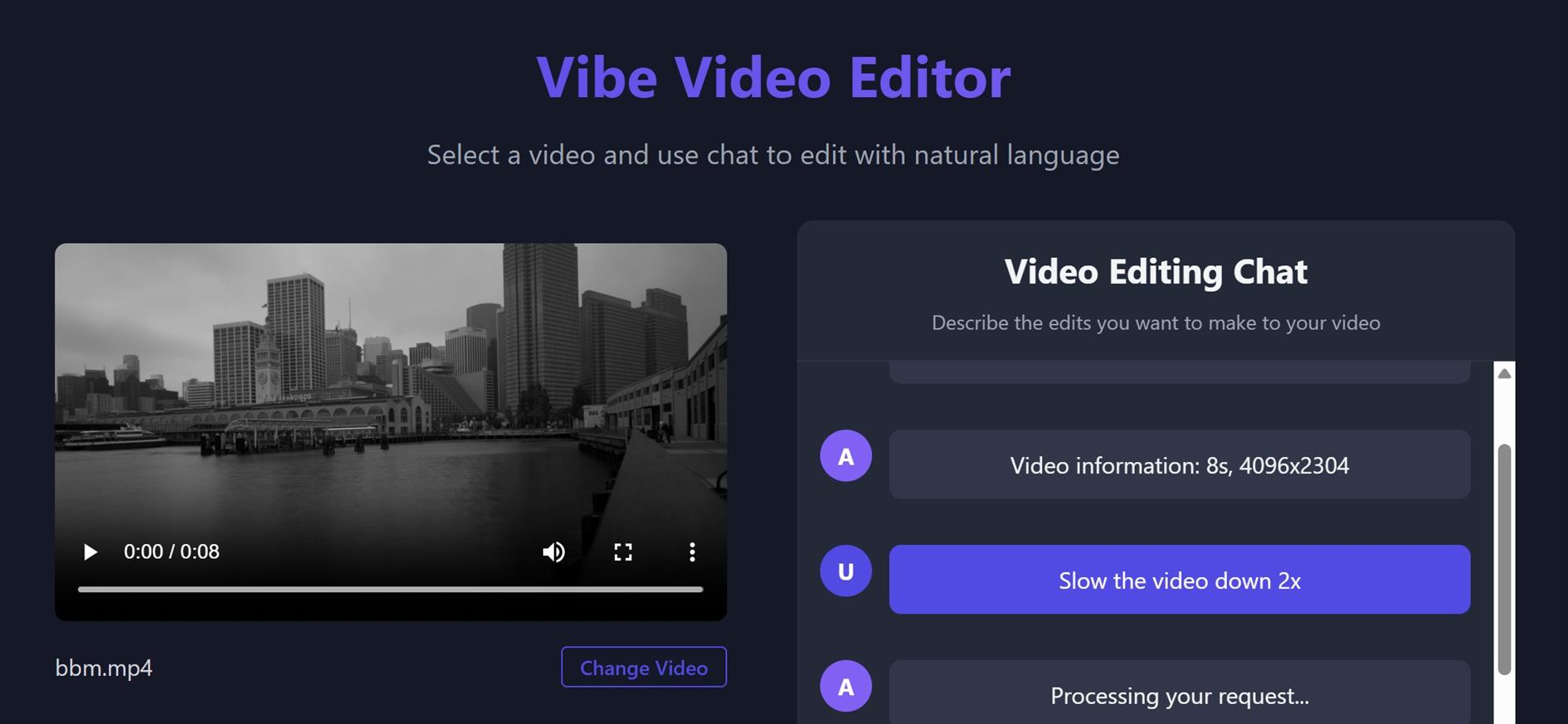
I set myself the goal this morning of shipping a vibe coded web application in a day. Welcome to the world, vibevideo.xyz, and apologies if you own Adobe stock.
Vibe Video is a chat based video editor. There are two things that are pretty cool about it. First, it writes its own code. When you ask it to make an edit it uses GPT 4.1 to write a function for the edit and then runs that function. That's the Vibe Video part. It's a single page JavaScript application but the core functionality is hallucinated at runtime.
Second, it runs locally. It's based on ffmpeg.wasm, which I knew nothing about before this morning. The site is a Vite/Svelte SPA deployed to a Cloudflare site with no backend except the OpenAI API. Your videos never leave your computer, and all the editing happens in the browser thanks to WebAssembly. I hadn't touched Vite or Svelte before today either.
Both of those things are crazy. There are some limitations - as the great saying goes, "If you are not embarrassed by the first version of your product, you’ve launched too late.". Right now you need to bring your own OpenAI API Key. Maybe I'll add some free usage when I get a grip on how much it costs to run. It's fast when you don't need to reencode - so trimming the video is quick. but changing resolution or speed will take some time. And there is a 2GB limit on file sizes, a limitation of WebAssembly. My hope is to iterate and improve, so kick the tires and let me know what else it needs.
To build this I used Visual Studio Code with GitHub Copilot in agent mode using Claude 3.7. The only code that's hand crafted is changing GPT 4 Turbo to GPT 4.1 (Claude refused to admit that 4.1 exists) and repeatedly removing a call to a non-existent file size property. While I didn't have to write any significant code I did need to coax the LLM - an experience halfway between being a product manager and pair programming with a buddy who is a much faster typist and won't allow you to touch the keyboard. There was a fair bit of troubleshooting involved as well, some with the environment setup and some with runtime errors. Having the experience to help guide Copilot through these helped a lot.
I have been experimenting with a lot of different tools over the past few weeks. Cursor and Windsurf both worked well for me, Replit was pretty good as well. Cline impressed me with debugging an app after building it. V0 and Lovable struggled with my test use case. I used Copilot for this personal experiment as I already have a license and wanted to see how far it would go. All of these tools are going to continue to improve (and/or merge). The current state of the art is a big deal already. A few weeks ago the statement that a good chunk of Y Combinator startups were writing 95%+ of their code with AI sounded like bullshit. Now I think they might be sandbagging.
One bad smell is that the experience gets worse as you add code. The start of the project was unbelievably easy, but as features were added Copilot started to bog down. This is unsurprising as the more you load up the context window for an LLM the more it struggles with the details. Again, this will just improve over time as models and agentic implementations improve. Good architecture is also going to matter - and is no different here from freeing regular developers from needing to keep too much in their head at the same time.
Related Posts
- Rob 2.0
- DeepCoder
- Adding AI to Todoist with Google Apps Script and OpenAI
- Style Transfer for Time Lapse Photography
- Download a Sharepoint File with GraphServiceClient (Microsoft Graph API)
(Published to the Fediverse as: Vibe Coding a Vibe Video Editor #code #ai #vibe #openai #llm #anthropic How I built a video editing service in a day with GitHub Copilot and ffmpeg.wasm )
Begging Carp

Google Pixel 8 Pro 18mm f2.8 1/450s ISO120
A carp begs for food in Spreckels Lake, Golden Gate Park.
Related Posts
(Published to the Fediverse as: Begging Carp #photo #carp #goldengatepark Photo of a carp begging for a snack in Spreckels Lake, Golden Gate Park, California )
Sunset Dunes

Sunset Dunes is the newest park in San Francisco, created in the November 2024 election by a controversial ballot measure. It's a two mile stretch of the Great Highway that was often closed due to drifting sand. The road was also closed to traffic during the pandemic, a move popular enough to get enough support to convert it to a full time park. Many people are mad with this development due to traffic spilling onto neighboring streets and increased commute times, to the extent that there is a recall campaign against the local supervisor. I'm bored of recall campaigns and NIMBYs and voted in favor of the new park.
The video below is a hyperlapse of the two miles from the Golden Gate Park to Sloat Boulevard through Sunset Dunes and then the two miles back on Ocean Beach.
Not much has changed since the pandemic experience. This isn't surprising as the ballot measure didn't add any funding for the park. The two sides of the original Great Highway are divided into a slow lane and a fast lane which makes sense. There are a few street murals and art installations dotted along the road which are fine but seem beside the point. I hope this remains as a safe space to cycle, scoot, board and stroll.
Hike starts at: 37.767321, -122.509288. View in Google Earth.
Related Posts
- Remnants in the Sunset
- Sand on Great Highway
- Lands End
- GGNRA Dog Management Round 3
- Golden Gate Park - Stow Lake, Strawberry Hill and Museum Concourse
(Hike Map)
(Published to the Fediverse as: Sunset Dunes #hike #greathighway #sunsetdunes #sanfrancisco #video #hikevid #sfdogwalk #oceanbeach #ggp #map Four mile hike down the Sunset Dunes park and then up Ocean Beach in San Francisco, California.</span> )
FRA BUD

Google Pixel 8 Pro 2mm f2.0 1/800s ISO41
LH1336
Related Posts
(Published to the Fediverse as: FRA BUD #photo #plane #fra #bud FRA BUD )
Vernal (Spring) Equinox 2025
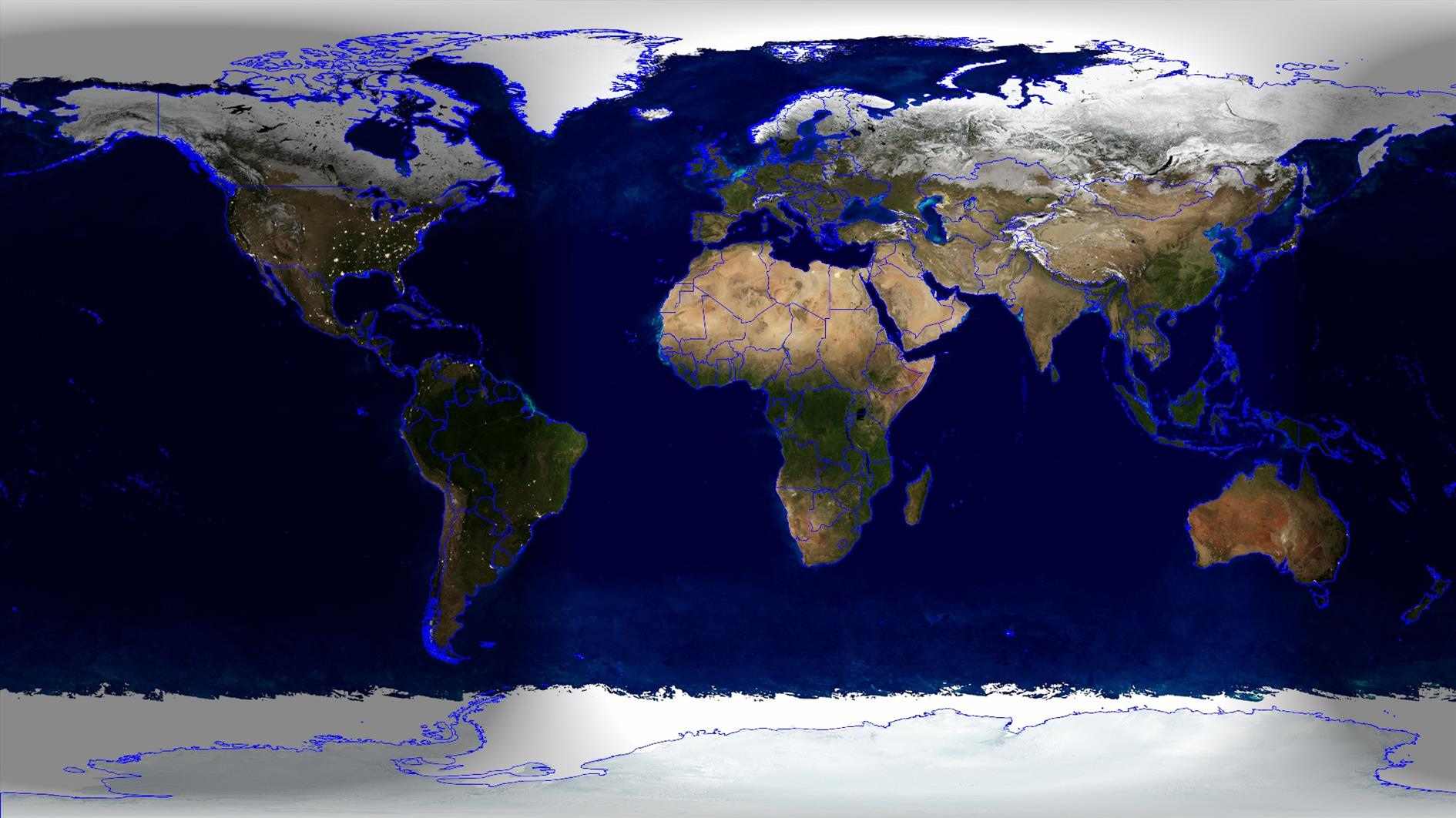
Spring has sprung (09:02 UTC, March 20, 2025) for the Northern Hemisphere and Autumn is here if you are south of the Equator. Rendered in Catfood Earth.
Related Posts
- Autumnal Equinox 2024
- Winter Solstice 2024
- Catfood Earth
- Animation of a year of Global Cloud Cover
- Improving the accuracy of the new Catfood Earth clouds layer
(Published to the Fediverse as: Vernal (Spring) Equinox 2025 #code #earth #catfood #equinox #spring #vernal #autumn The exact moment (09:02 UTC, March 20, 2025) of the Spring Equinox in Catfood Earth. )
Building a Digital Photo Frame

Google recently bricked my digital photo frame, so I set out to build a new one. I did this in two parts - a Raspberry Pi to display the photos, and a C# script to preprocess them. The second part is optional but worth it.
The display side of the project turned out to be way easier than I thought. There is a utility called fbi that will run a slideshow to a HDMI monitor. Create a boot SD card from the lite version of Raspberry PI OS, copy over your photos and then run:
sudo apt-get update sudo apt-get -y install fbi
You can then connect a monitor and test that images are displaying as expected.
Create a file called launch.sh with the following:
#!/bin/sh # launch.sh # run photos sleep 2m fbi -T 1 -noverbose -mode 1366x768-30 -t 60 -u -blend 1500 -a /home/rob/photos/*.jpg
-T 1 uses the first display, -noverbose just shows the photos, -mode depends on your monitor and is likely safe to omit, -t 60 changes the image ever sixty seconds, -u displays in a random order, -blend 1500 cross fades for 1.5 seconds between images, -a is auto zoom and the path at the end is where ever you copied your photos to.
The sleep 2m command allows the system to complete booting and bring up the login prompt. Without this the photos might start first and then the login shell ends up on top, which is pretty boring.
Make the script executable (chmod 755 launch.sh) and then edit your crontab:
sudo crontab -e
Add the following:
@reboot sh /home/rob/launch.sh >/home/rob/logs/cronlog 2>&1 30 22 * * * /sbin/shutdown -h now
The first line runs the launch.sh script at startup and sends any output to a log file (adjust paths to your system). The second line will shut down the Pi at 10:30pm every day. I use this so I can control when it's running with a smart plug - the plug turns everything on at 7am and off at 10:45pm, and the shutdown prevents the Pi from getting in a bad state from having power removed unceremoniously. If you want it running all the time just omit this line.
Reboot and you should have a working digital photo frame. Fbi will do a reasonable job with your photos, but I wanted something better.
The C# script below preprocesses all my photos to make the best use of the frame. I'm using an old 1366x768 TV so I want all the photos at that resolution and 16x9 aspect ratio. Many of my photos are 4x3, or 3x4, or 9x16, or something else entirely. I don't want any black borders so cropping will be involved.
Cropping is handled by detecting faces and then trying to keep as many in frame as possible. This uses FaceAiSharp.
Photos are processed in two stages. The first stage just crops horizontal photos to fit the screen. Any vertical photos are saved in a list, and then paired using image embeddings (CLIP using this code). My implementation pairs the most similar photos - it would be easy to do the most different as well.
Here's the code. I run this with C# 9 in VSCode on Windows. You'll probably want to change the input and output folders, and possibly the output resolution as well:
| using SixLabors.ImageSharp; | |
| using SixLabors.ImageSharp.Processing; | |
| using SixLabors.ImageSharp.PixelFormats; | |
| using SixLabors.ImageSharp.Formats.Jpeg; | |
| using FaceAiSharp; | |
| using System.Numerics.Tensors; | |
| using Microsoft.ML.OnnxRuntime; | |
| using Microsoft.ML.OnnxRuntime.Tensors; | |
| const string InputFolder = @"D:\photo-frame\input"; | |
| const string OutputFolder = @"D:\photo-frame\output"; | |
| const int OutputWidth = 1366; | |
| const int OutputHeight = 768; | |
| const float OutputAspectRatio = (float) OutputHeight / OutputWidth; | |
| int fileNumber = 0; | |
| Console.WriteLine("photo-frame-process"); | |
| ImageEmbedder imageEmbedder = new ImageEmbedder(); | |
| var faceDetector = FaceAiSharpBundleFactory.CreateFaceDetectorWithLandmarks(); | |
| Random rng = new Random(); | |
| List<MetaImage> metaImages = new List<MetaImage>(); | |
| DirectoryInfo di = new DirectoryInfo(InputFolder); | |
| string[] extensions = { "*.jpg", "*.jpeg", "*.png", "*.gif", "*.webp" }; | |
| List<FileInfo> files = new List<FileInfo>(); | |
| foreach(string ext in extensions) | |
| { | |
| files.AddRange(di.GetFiles(ext, SearchOption.AllDirectories)); | |
| } | |
| foreach(FileInfo file in files) | |
| { | |
| // debug single image | |
| //if (file.Name != "IMG_1023.JPG") { continue; } | |
| Console.Write(file.Name); | |
| using (Image<Rgb24> image = Image.Load<Rgb24>(file.FullName)) | |
| { | |
| image.Mutate(i => i.AutoOrient()); | |
| float aspect = (float) image.Height / image.Width; | |
| // happiest path - same aspect ratio | |
| if (aspect == OutputAspectRatio) | |
| { | |
| Console.WriteLine(" - same aspect ratio"); | |
| image.Mutate(x => x.Resize(OutputWidth, OutputHeight)); | |
| image.SaveAsJpeg(GetNextFileName(), new JpegEncoder {Quality = 90}); | |
| continue; | |
| } | |
| // vertical image | |
| if (image.Width < image.Height) | |
| { | |
| Console.WriteLine(" - vertical image"); | |
| metaImages.Add(new MetaImage(file.FullName, imageEmbedder.Embed(file.FullName))); | |
| continue; | |
| } | |
| // horizontal image | |
| Console.WriteLine(" - horizontal image"); | |
| try | |
| { | |
| FaceAwareResize(image, OutputWidth, OutputHeight); | |
| image.SaveAsJpeg(GetNextFileName(), new JpegEncoder {Quality = 90}); | |
| } | |
| catch (Exception ex) | |
| { | |
| Console.WriteLine($"Error processing {file.FullName}: {ex.Message}"); | |
| } | |
| } | |
| } | |
| while(metaImages.Count > 0) | |
| { | |
| if (metaImages.Count == 1) | |
| { | |
| // one left over image, just resize as best as possible... | |
| MetaImage metaImage = metaImages[0]; | |
| metaImages.Remove(metaImage); | |
| Console.WriteLine($"{Path.GetFileName(metaImage.ImagePath)} - single vertical image"); | |
| using (Image<Rgb24> image = Image.Load<Rgb24>(metaImage.ImagePath)) | |
| { | |
| try | |
| { | |
| image.Mutate(i => i.AutoOrient()); | |
| FaceAwareResize(image, OutputWidth, OutputHeight); | |
| image.SaveAsJpeg(GetNextFileName(), new JpegEncoder {Quality = 90}); | |
| } | |
| catch (Exception ex) | |
| { | |
| Console.WriteLine($"Error processing {metaImage.ImagePath}: {ex.Message}"); | |
| } | |
| } | |
| break; | |
| } | |
| // find two vertical images to combin | |
| MetaImage meta1 = metaImages[rng.Next(metaImages.Count)]; | |
| MetaImage? meta2 = null; | |
| float bestSimilarity = float.MinValue; | |
| // find the second image that is closest to the first image based on cosine similarity | |
| foreach(MetaImage candidate in metaImages) | |
| { | |
| if (candidate == meta1) | |
| { | |
| continue; | |
| } | |
| float similarity = TensorPrimitives.CosineSimilarity(meta1.Embedding, candidate.Embedding); | |
| if (similarity > bestSimilarity) | |
| { | |
| bestSimilarity = similarity; | |
| meta2 = candidate; | |
| } | |
| } | |
| if (meta2 == null) | |
| { | |
| throw new Exception("No second image found"); | |
| } | |
| metaImages.Remove(meta1); | |
| metaImages.Remove(meta2); | |
| Console.WriteLine($"{Path.GetFileName(meta1.ImagePath)} - vertial image paired with {Path.GetFileName(meta2.ImagePath)}"); | |
| try | |
| { | |
| using (Image<Rgb24> image1 = Image.Load<Rgb24>(meta1.ImagePath)) | |
| { | |
| image1.Mutate(i => i.AutoOrient()); | |
| using (Image<Rgb24> image2 = Image.Load<Rgb24>(meta2.ImagePath)) | |
| { | |
| image2.Mutate(i => i.AutoOrient()); | |
| FaceAwareResize(image1, OutputWidth / 2, OutputHeight); | |
| FaceAwareResize(image2, OutputWidth / 2, OutputHeight); | |
| // create a new image with the two images combined | |
| using (Image<Rgb24> combinedImage = new Image<Rgb24>(OutputWidth, OutputHeight)) | |
| { | |
| combinedImage.Mutate(x => x.DrawImage(image1, new Point(0, 0), 1f)); | |
| combinedImage.Mutate(x => x.DrawImage(image2, new Point(OutputWidth / 2, 0), 1f)); | |
| combinedImage.SaveAsJpeg(GetNextFileName(), new JpegEncoder {Quality = 90}); | |
| } | |
| } | |
| } | |
| } | |
| catch (Exception ex) | |
| { | |
| Console.WriteLine($"Error processing {meta1.ImagePath} and {meta2.ImagePath}: {ex.Message}"); | |
| } | |
| } | |
| Console.WriteLine("photo-frame-process done!"); | |
| // utility below | |
| void FaceAwareResize(Image<Rgb24> image, int width, int height) | |
| { | |
| RectangleF? detectRect = null; | |
| var faces = faceDetector.DetectFaces(image); | |
| foreach(var face in faces) | |
| { | |
| if (detectRect.HasValue) | |
| { | |
| detectRect = RectangleF.Union(detectRect.Value, face.Box); | |
| } | |
| else | |
| { | |
| detectRect = face.Box; | |
| } | |
| } | |
| RectangleF coreRect = detectRect ?? new RectangleF(image.Width / 2.0f, image.Height / 2.0f, 0.1f, 0.1f); | |
| // get the center of coreRect as PointF | |
| PointF center = new PointF(coreRect.X + coreRect.Width / 2.0f, coreRect.Y + coreRect.Height / 2.0f); | |
| float targetAspectRatio = (float) width / height; | |
| float imageAspectRatio = (float) image.Width / image.Height; | |
| if (targetAspectRatio >= imageAspectRatio) | |
| { | |
| // figure out the best Y position | |
| float targetHeight = image.Width * ((float)height / width); | |
| float y = center.Y - targetHeight / 2.0f; | |
| if (y < 0) | |
| { | |
| y = 0; | |
| } | |
| else if (y + targetHeight > image.Height) | |
| { | |
| y = image.Height - targetHeight; | |
| } | |
| int intY = (int)y; | |
| int intTargetHeight = (int)targetHeight; | |
| int extra = image.Height - (intY + intTargetHeight); | |
| if (extra < 0) | |
| { | |
| intTargetHeight += extra; | |
| } | |
| Rectangle targetRect = new Rectangle(0, intY, image.Width, intTargetHeight); | |
| // crop to targetRect | |
| image.Mutate(x => x.Crop(targetRect)); | |
| } | |
| else | |
| { | |
| // figure out the best X position | |
| float targetWidth = image.Height * ((float)width / height); | |
| float x = center.X - targetWidth / 2.0f; | |
| if (x < 0) | |
| { | |
| x = 0; | |
| } | |
| else if (x + targetWidth > image.Width) | |
| { | |
| x = image.Width - targetWidth; | |
| } | |
| int intX = (int)x; | |
| int intTargetWidth = (int)targetWidth; | |
| int extra = image.Width - (intX + intTargetWidth); | |
| if (extra < 0) | |
| { | |
| intTargetWidth += extra; | |
| } | |
| Rectangle targetRect = new Rectangle(intX, 0, intTargetWidth, image.Height); | |
| // crop to targetRect | |
| image.Mutate(x => x.Crop(targetRect)); | |
| } | |
| // Resize the image to the target dimensions while keeping the face in the center | |
| image.Mutate(x => x.Resize(new ResizeOptions | |
| { | |
| Size = new Size(width, height) | |
| })); | |
| } | |
| string GetNextFileName() | |
| { | |
| fileNumber++; | |
| return Path.Combine(OutputFolder, $"{fileNumber:00000000}.jpg"); | |
| } | |
| internal class MetaImage | |
| { | |
| public string ImagePath { get; set; } | |
| public float[] Embedding { get; set; } | |
| public MetaImage(string imagePath, float[] embedding) | |
| { | |
| ImagePath = imagePath; | |
| Embedding = embedding; | |
| } | |
| } | |
| /// <summary> | |
| /// Embeds an image using the OpenAI CLIP model. | |
| /// See https://github.com/bartbroere/clip.dll/blob/master/Program.cs | |
| /// </summary> | |
| internal class ImageEmbedder | |
| { | |
| private InferenceSession _model; | |
| public ImageEmbedder() | |
| { | |
| if (!File.Exists("clip-image-vit-32-float32.onnx")) | |
| { | |
| using (HttpClient httpClient = new HttpClient()) | |
| { | |
| var response = httpClient.GetAsync("https://huggingface.co/rocca/openai-clip-js/resolve/main/clip-image-vit-32-float32.onnx").Result; | |
| using (var fs = new FileStream("clip-image-vit-32-float32.onnx", FileMode.CreateNew)) | |
| { | |
| response.Content.CopyToAsync(fs).Wait(); | |
| } | |
| } | |
| } | |
| _model = new InferenceSession("clip-image-vit-32-float32.onnx"); | |
| } | |
| public float[] Embed(string imagePath) | |
| { | |
| return Embed(Image.Load<Rgb24>(File.ReadAllBytes(imagePath))); | |
| } | |
| public float[] Embed(Image<Rgb24> image) | |
| { | |
| var smallestSide = Math.Min(image.Width, image.Height); | |
| image.Mutate(x => x.Crop( | |
| new Rectangle( | |
| (image.Width - smallestSide) / 2, | |
| (image.Height - smallestSide) / 2, | |
| smallestSide, | |
| smallestSide | |
| ))); | |
| image.Mutate(x => x.Resize(224, 224)); | |
| var inputTensor = new DenseTensor<float>(new[] {1, 3, 224, 224}); | |
| for (var x = 0; x < 224; x++) | |
| { | |
| for (var y = 0; y < 224; y++) | |
| { | |
| // Normalize from bytes (0-255) to floats (constants borrowed from CLIP repository) | |
| inputTensor[0, 0, y, x] = Convert.ToSingle((((float) image[x, y].R / 255) - 0.48145466) / 0.26862954); | |
| inputTensor[0, 1, y, x] = Convert.ToSingle((((float) image[x, y].G / 255) - 0.4578275 ) / 0.26130258); | |
| inputTensor[0, 2, y, x] = Convert.ToSingle((((float) image[x, y].B / 255) - 0.40821073) / 0.27577711); | |
| } | |
| } | |
| var inputs = new List<NamedOnnxValue> {NamedOnnxValue.CreateFromTensor("input", inputTensor)}; | |
| var outputData = _model.Run(inputs).ToList().Last().AsTensor<float>().ToArray(); | |
| return outputData; | |
| } | |
| } |
Related Posts
- Style Transfer for Time Lapse Photography
- Fastest image merge (alpha blend) in GDI+
- Predicting when fog will flow through the Golden Gate using ML.NET
- Long term solar powered time lapse camera using Arduino
- Capture DropCam (Nest Cam) frames to Google Drive
(Published to the Fediverse as: Building a Digital Photo Frame #code #c# #raspberrypi #ai #ml How to create a Raspberry Pi based digital photo frame with face aware cropping and AI image pairing. )

